tel 010-61934861
mail tm@tsingmicro.com
add 北京市海淀区宝盛南路1号院26号楼领智中心南楼2层
k8凯发首页 / 新闻
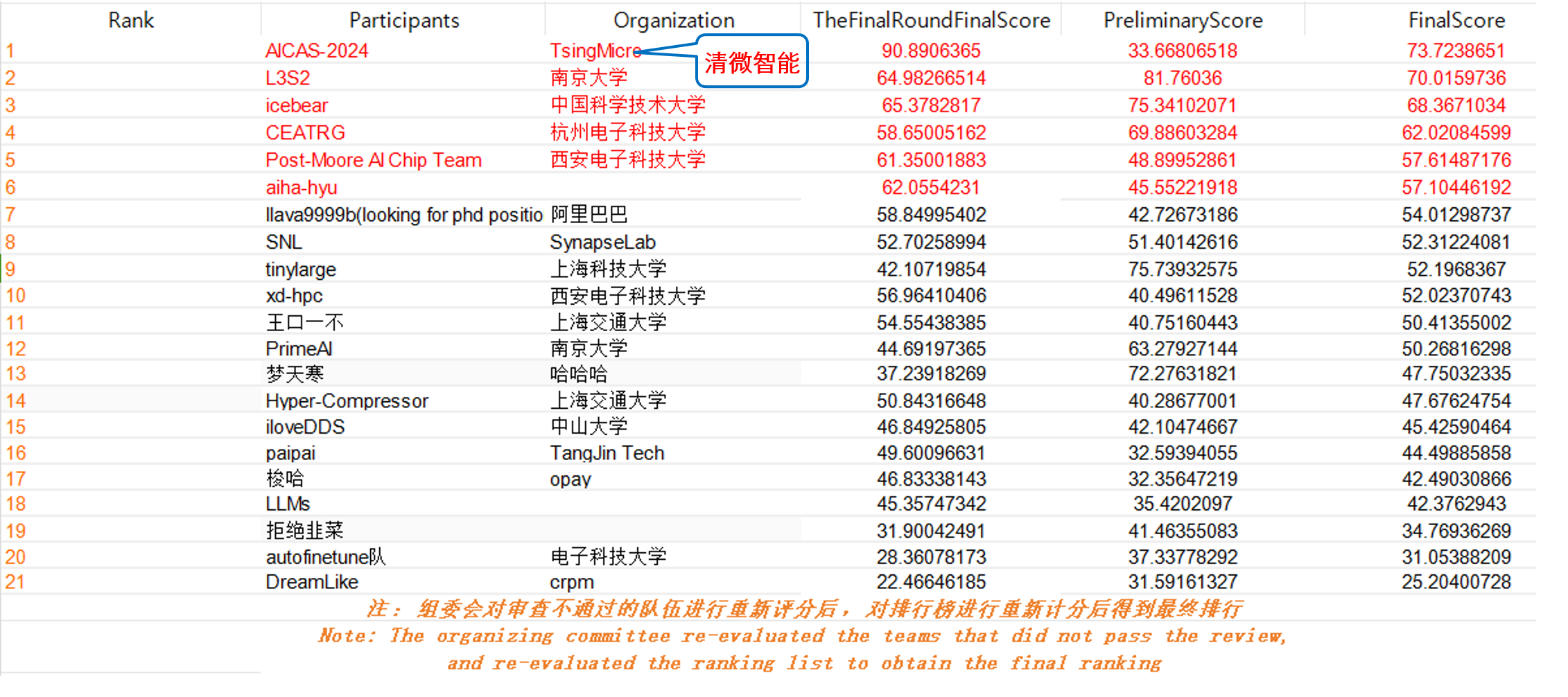
清微智能可重构工具链团队夺得2024 ieee aicas 国际通用算力大模型优化挑战赛第一名
time:2024年6月21日 | author:清微智能
专注于ai硬件的实现、类脑计算和学习算法等领域的aicas,是ieee的旗舰会议,也是该领域最受好评的年度会议之一。aicas 2024 grand challenge大模型优化国际挑战赛是该会议的重要活动之一,共吸引了包括达摩院
大语言模型(large language models
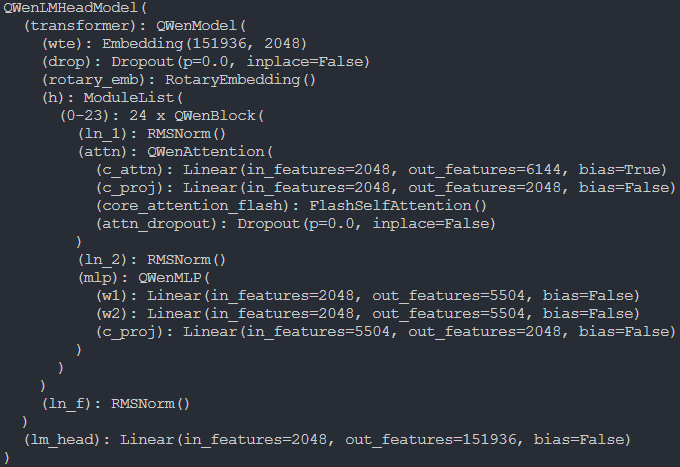
本次比赛采用的是阿里qwen1.8b模型,其主要结构如下图所示,相较于传统的transfomer,主要区别在于:
1)采用rms norm代替layernorm;
2)采用swiglu
3)采用rope
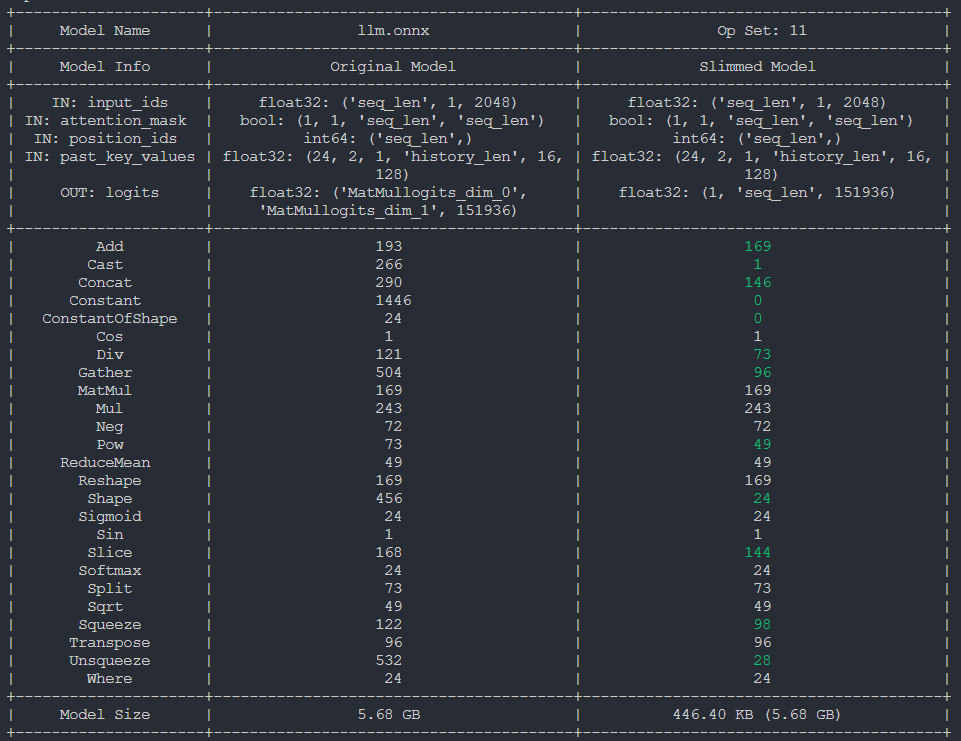
比赛流程中会将pytorch模型先转到onnx上面,对onnx优化完成之后再进行部署。清微工具链团队推出了onnxslim优化工具,特别针对大模型做优化。
清微智能工具链团队推出跨平台(windows, linux, mac; x86, arm)onnx模型优化工具onnxslim,针对qwen1.8b模型,优化后算子个数减少约40%,同时推理性能提升约10%。
1. 算子输出形状推理
onnxslim图优化强烈依赖形状推理,当算子输出形状推理出来之后,可以根据具体形状做优化。以下左图为例:
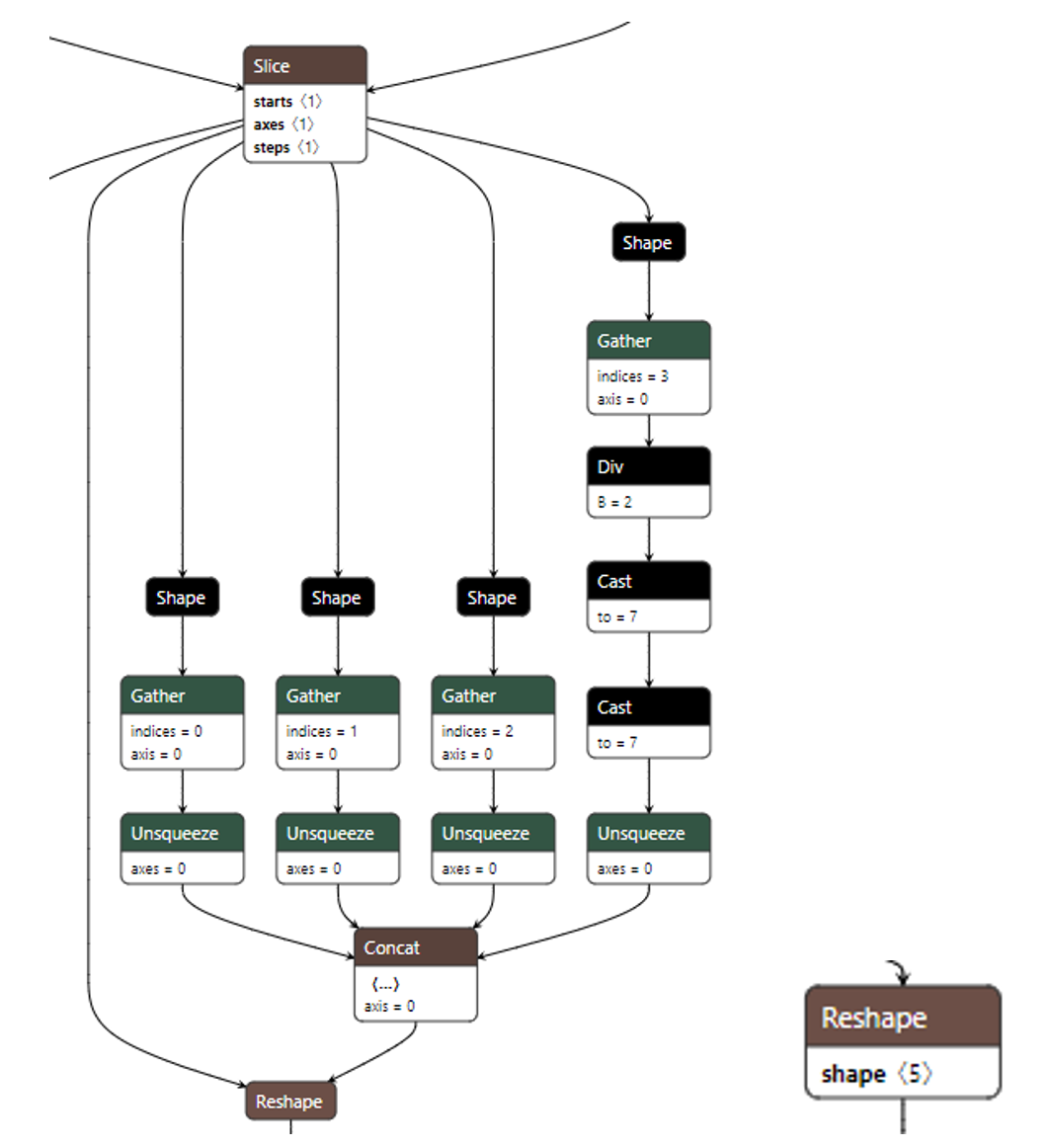
当reshape算子的输出形状推理出为(1, dynamic_dim, 16, 2, 64)时,onnxslim会将reshape算子右路所有需要计算的部分删除掉,优化结果为上右图。
2. 算子常量折叠
常量折叠主要用于优化子图中输入为常量的情况,以下左图为例:
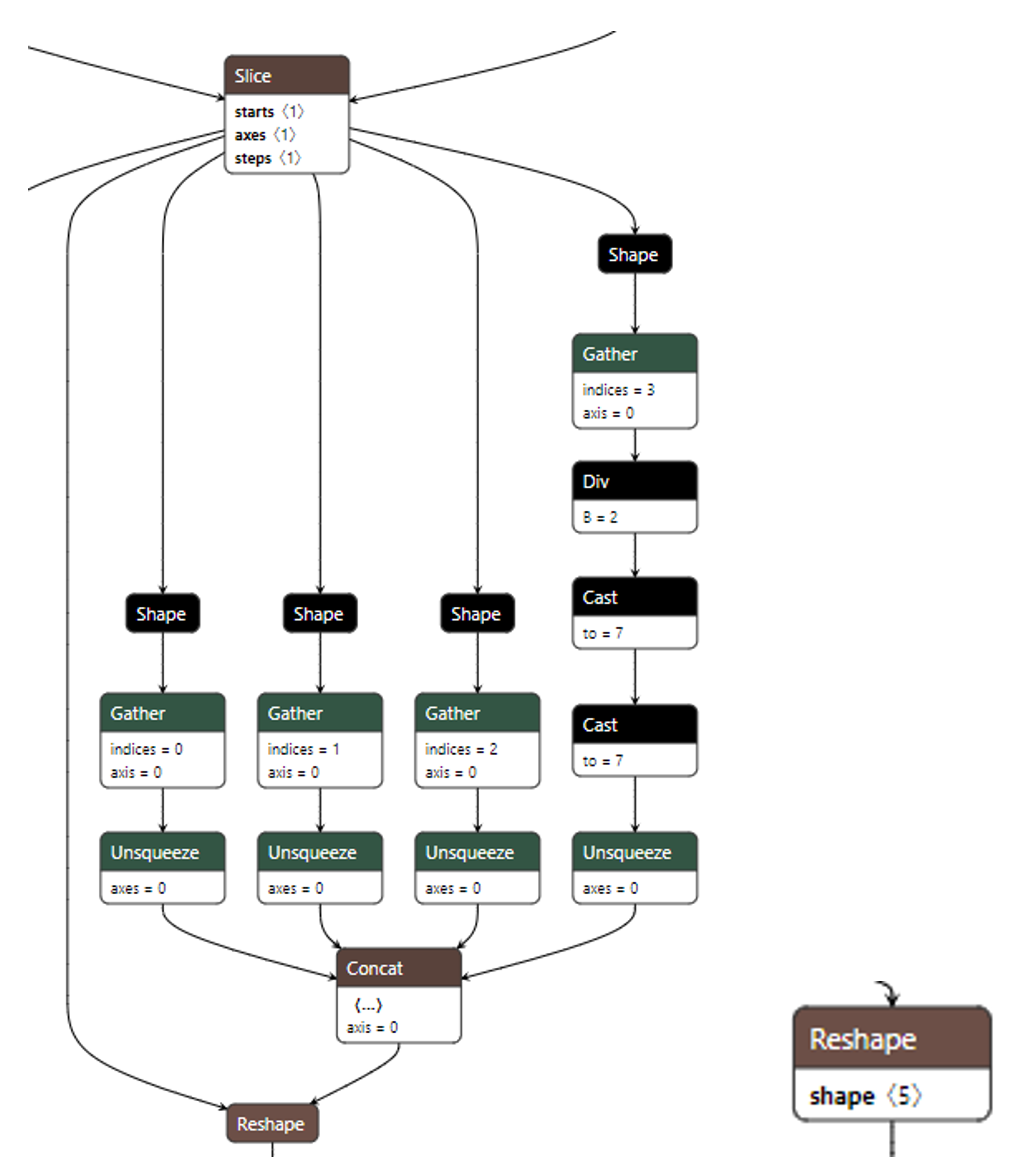
当所有shape算子的输出都为常量时,可以通过实际推理一次模型,然后将concat算子的输出,作为reshape算子的第二路输入,从而删除shape算子到concat算子这个子网络,优化结果为上右图。
3. 算子融合
算子融合可以将多个算子合并成一个算子,这样可以减少内存占用以及计算开销,提升硬件利用率并降低推理延迟。以下左图为例:

当两个级联的slice算子满足一定条件时,可以被融合成一个,如上右图所示。
4. 公共子图消除
公共子图消除是编译器常用的一种优化技术,它的主要目标是减少程序中重复的计算,通过识别和消除重复的计算来提高程序的性能。以下左图为例:
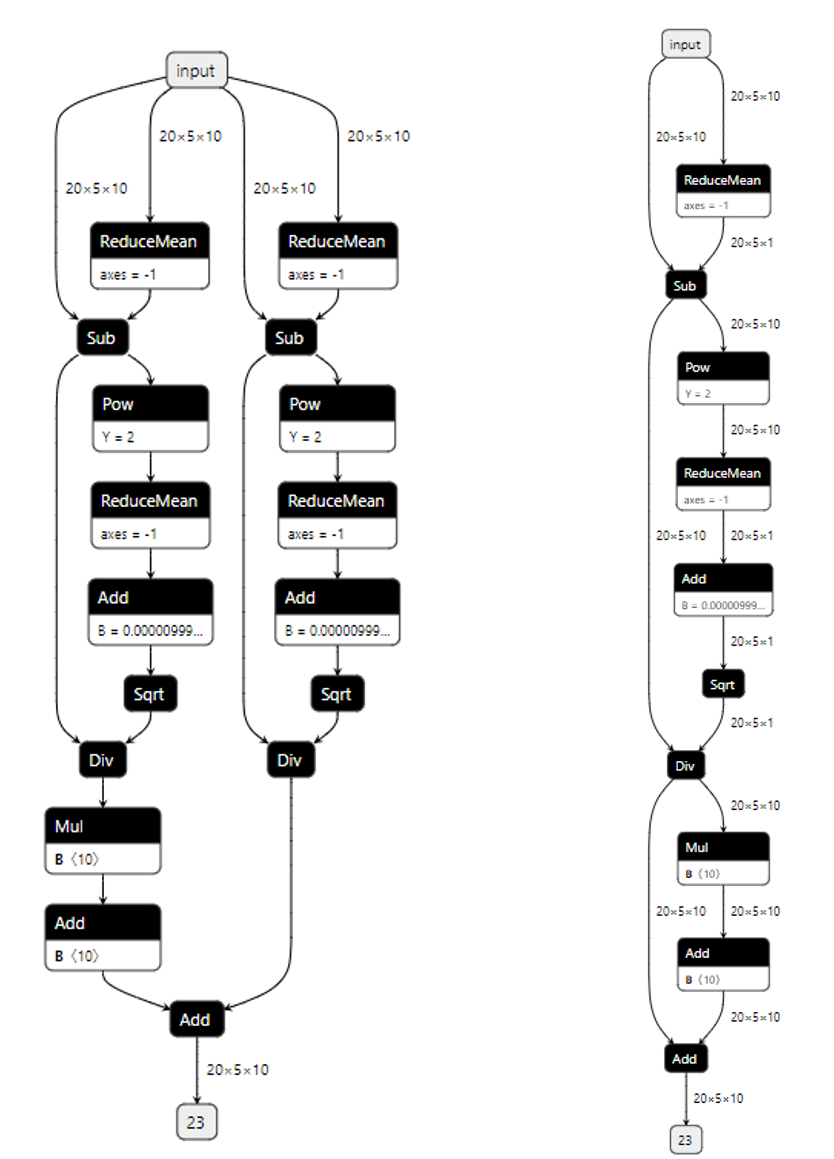
左上图中两个reducemean算子输入和属性完全一致,可以通过公共子图算法融合到一起,以此类推,直到div算子都可以被融合到一起。优化结果为上右图。
清微骑士工具链提供一整套从算法到应用的全栈式加速工具,支持清微智能云端大算力,边缘端中算力芯片全系列产品落地,兼容市面上主流的tensorflow、pytorch、caffe、keras、onnx等学习框架,支持llama、chatglm等国内外大模型部署。清微智能工具链团队在开源社区持续贡献自己的力量,是mnn、ncnn、tensorrt、onnxruntime、pytorch等多个开源项目的贡献成员,已完成与百度paddlepaddle iii级兼容性认证,支持涉及视觉,自然语言处理和推荐的30多个模型。清微工具链以强大的兼容性和高效的易用性,推动人工智能尤其人工智能大模型的发展。
k8凯发 copyright © 2019 tsing micro.com.cn all rights reserved 清微智能 凯发k8官网登录vip的版权所有